Ein Bot lernt fahren...¶
Eines der größten Probleme bei diesem Projekt war die Erstellung von geeigneten Trainingsdaten. In diesem Fall von Bildern, die verschiedene Fälle wie “geradeaus Fahren” oder “stehen bleiben” abbilden. Dabei besteht die Schwierigkeit, dass der Roboter einen geeigneten Untergrund benötigt. Dieser soll es ihm ermöglichen, die prägnantesten visuellen Merkmale der Straße zu erlernen. Bietet der Untergrund keinen ausreichenden Kontrast, so kann er keine Merkmale erlernen. Um diesem Anspruch gerecht zu werden, benutzen wir Lego-Straßen. Die Lego-Platten haben in der Mitte eine graue Fahrbahn, die außen durch einen Grünstreifen abgegrenzt wird. Mit diesem kontrastreichem Bild sollten ausreichend Merkmale erlernbar sein.
Szenario 1: Binäre Klassifikation¶
Download: Beispieldaten + Code
In diesem ersten Szenario möchten wir zwei Fälle unterscheiden:
- Der Bot erkennt eine leere Straße und fährt geradeaus.

- Der Bot erkennt ein Hindernis und bleibt stehen (Kollisionsvermeidung).

Wir importieren alle nötigen Module, definieren die Dimensionen der verwendeten Bilder und verweisen auf die Pfade der Trainings- und Validierungsdaten:
import os
import numpy as np
from time import time
from keras.callbacks import TensorBoard
from keras.models import Sequential
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import Convolution2D, MaxPooling2D, ZeroPadding2D
from keras import optimizers
from keras import applications
from keras.models import Model
# Dimensionen der Bilder
img_width, img_height = 160,120
# Pfadangaben der Trainings- und Validierungsdaten
train_data_dir = './data/train'
validation_data_dir = './data/validation'
Im nächsten Schritt werden die Bilder vorverarbeitet. Wir reduzieren die Pixelwerte, die im RGB-Farbraum zwischen 0 und 255 liegen zu einem Intervall von 0 bis 1 und legen die Batch Size fest. Wir werden später untersuchen, ob die Größe der Batch Size eine Auswirkung auf das trainierte Modell hat.
Anschließend holen wir die Bilder und ihre Klassen.
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 128
train_generator = datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
validation_generator = datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
Wir schreiben einen einfachen Stapel von drei convolutionellen Layern mit einer ReLU Aktivierungsfunktion, gefolgt von Max-Pooling Layern. Anschließend kompilieren wir das Modell und legen dabei die Parameter fest: Die Kostenfunktion ist eine binary_crossentropy, der Optimizer ist “rmsprop”, metrics ist “accuracy”.
model = Sequential()
model.add(Convolution2D(32, (3, 3), \
input_shape=(img_width, img_height,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
Nach diesem dreier Stapel von Convolutions folgt die eigentliche Klassifizierungsarbeit. Flatten überführt die mehrdimensionalen Vektoren aus den Convolutions in eindimensionale Vektoren. Dropout reduziert das Overfitting.
Abschließend legen wir fest, wieviele Epochen wir berechnen möchten, wie viele Trainings- und Validierungsdaten wir haben und starten dann ein TensorBoard, um die Berechnungen zu visualisieren.
In der letzten Zeile speichern wir das Modell. Auf dem verwendeten Rechner (AMD RyZen 1700X mit 16 logischen Kerne @ 3,9 GHZ und 32GB DDR4) rechnet das Modell ca. 10 Minuten. TensorFlow ist für die Instruktionen SSE, AVX und FMA kompiliert. Wenn TensorFlow diese Befehlssätze benutzen kann, verringert sich die Rechenzeit enorm.
epochs = 50
train_samples = 1342
validation_samples = 403
tensorboard = TensorBoard(log_dir="logs/{}".format(time()))
model.fit_generator(
train_generator,
steps_per_epoch=train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=validation_samples // batch_size,
callbacks=[tensorboard])
model.save('./data/models/beispiel1.h5')
Ergebnisse
50 Epochen
Batch Size = 128
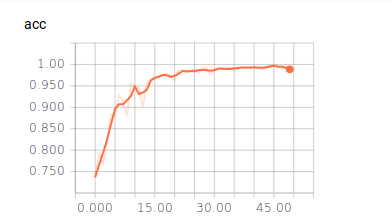
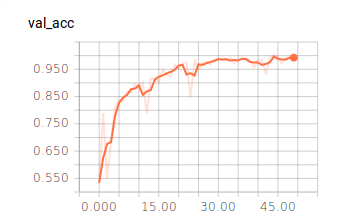
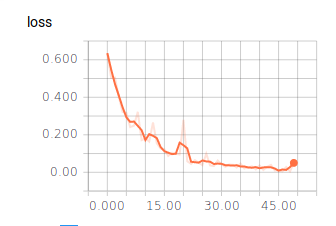
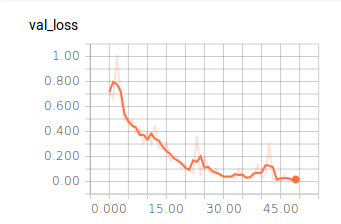
Vorhersage eines Bildes
from keras.models import load_model
from keras.preprocessing import image
import numpy as np
img_width, img_height = 160, 120
model = load_model('./data/models/beispiel1.h5')
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
img = image.load_img('stop2.png', target_size=(img_width, img_height))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
classes = model.predict_classes(x, batch_size=128)
print(classes)
200 Epochen
Wie bereits nach 50 Epochen zu erkennen ist, ändern sich die berechneten Werte nicht mehr. Sie erreichen eine Genauigkeit von ca. 98%. Trotzdem haben wir einen Test mit 200 Epochen durchlaufen lassen. Dieser bestätigt das bereits ermittelte Verhalten. Die Batch Size haben wir mit 128 eingestellt.
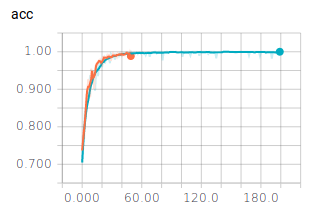
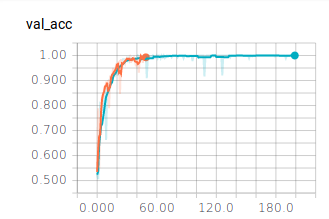
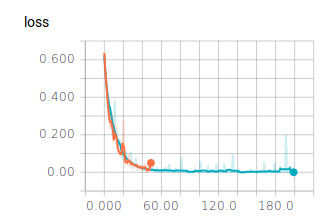
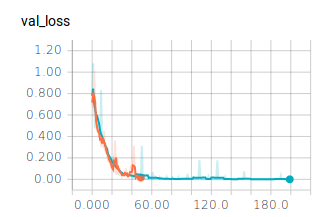
Modell Plotten
from keras.utils import plot_model
plot_model(model, to_file='model.png', show_shapes=True)
Die letzten beiden Zeilen plotten das verwendete TensorFlow Modell:
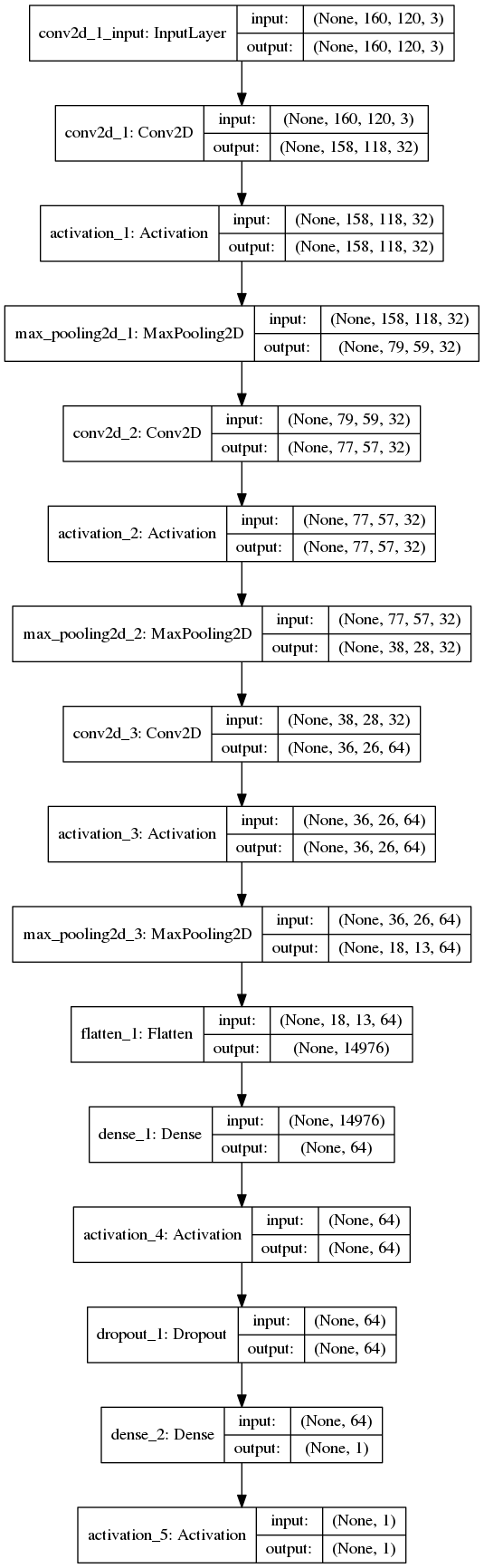
Batch Sizes
Alle Graphen werden im TensorBoard mit Smoothing = 0.6 dargestellt. Die ausgeblichenen Graphen im Hintergrund stellen die Graphen ohne Smoothing dar. Betrachten wir die Graphen für die unterschiedlichen Batch Sizes mit 50 Epochen:
- Orange: 128
- Lila: 256
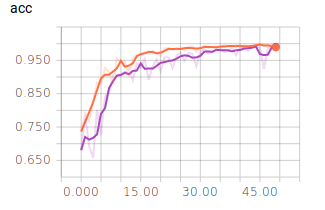
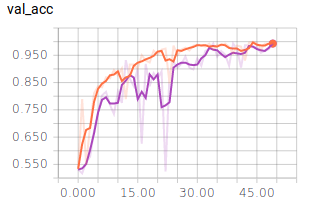
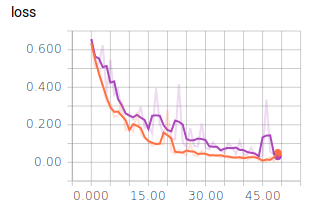
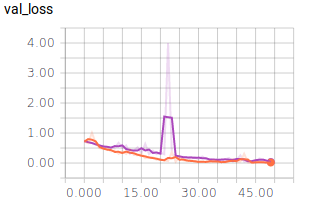
Nun nehmen wir noch die Graphen für die Batch Size = 10 in die Auswertung:
- Dunkel Blau: 10
- Orange: 128
- Lila: 256
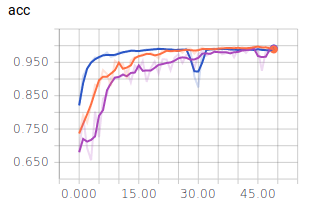
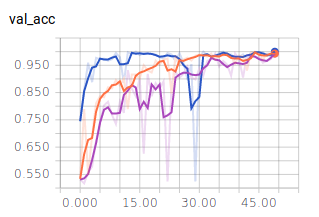
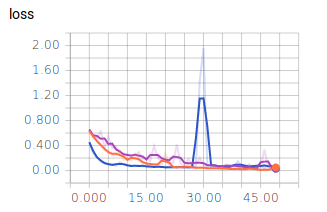
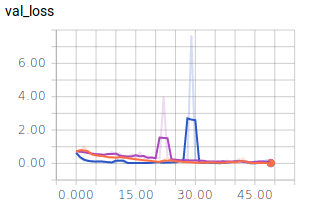
Es lässt sich ablesen, dass sehr kleine und sehr große Batch Sizes zu großen Ausreißern in den Graphen führen. Dennoch erreichen alle drei Batch Sizes ähnlich gute Ergebnisse und würden sich für ein zuverlässiges Modell eignen. Es ist jedoch festzuhalten, dass ein mittlerer Wert, wie es 128 ist, zu einem ausgewogenen Verlauf führt.
ReLu vs. Sigmoid
Wir ändern die Aktivierungsfunktionen in den Convolutions von ReLu zu Sigmoid:
model = Sequential()
model.add(Convolution2D(32, (3, 3), \
input_shape=(img_width, img_height,3)))
model.add(Activation('sigmoid'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(32, (3, 3)))
model.add(Activation('sigmoid'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, (3, 3)))
model.add(Activation('sigmoid'))
model.add(MaxPooling2D(pool_size=(2, 2)))

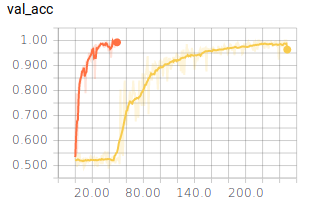

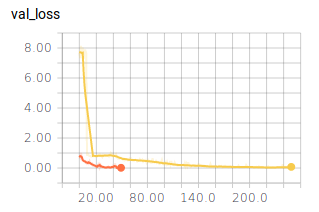
Die eingesetzten Sigmoidaktivierungsfunktionen sorgen dafür, dass das Training wesentlich länger dauert. Das Netz erreicht erst nach 200 Epochen ähnliche Werte wie bei der Verwendung von ReLu.
Anzahl der “Stapel”
Bislang haben wir das Netz mittels drei Stapeln der Abfolge
- Convolution2D,
- Activation,
- MaxPooling2D
trainiert.
Benutzen wir diese Abfolge häufiger bzw. geringer, ergibt dies folgenden Verlauf:
-Orange: Dreier Stapel
-Lila: Fünfer Stapel
-Braun: Einer Stapel
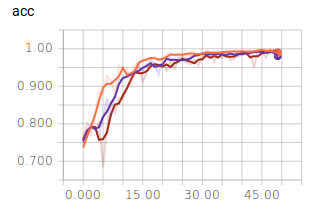
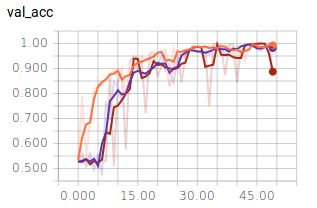
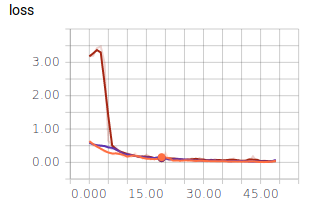
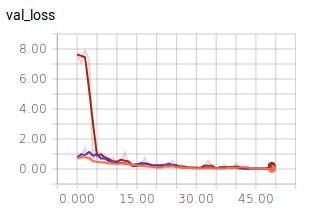
Wird nur ein Stapel benutzt, so zeigt der Graph deutliche Ausreißer. Der Unterschied zwischen fünf und drei Stapeln ist hingegen marginal. Dies zeigt, warum Bilderkennung auf “Deep Learning”, also viele aufeinander folgende Schichten angewiesen ist.
Szenario 2: Multi-Class Klassifikation¶
Download: Beispieldaten + Code
Im zweiten Szenario möchten wir drei Fälle unterscheiden:
- Der Bot erkennt eine leere Straße und fährt geradeaus.
- Der Bot erkennt eine Links- oder Rechtskurve und fährt in die entsprechende Richtung.


Für eine Multi-Klassifikation muss der bisherige Code ein wenig abgeändert werden:
- Wir setzen den class_mode beim Generator auf “categorical”,
- die vorletzte Aktivierungsfunktion ist vom Typ “ReLu”,
- die letzte Aktivierungsfunktion ist vom Typ “Softmax”,
- wir setzten nb_classes = 3 und
- kompilieren das Modell mit der Kostenfunktion = “categorical_crossentropy”.
Des Weiteren benutzen wir einen Stapel von drei convolutionellen Layern und trainieren 100 Epochen.
import os
import numpy as np
from time import time
from keras.callbacks import TensorBoard
from keras.models import Sequential
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import Convolution2D, MaxPooling2D, ZeroPadding2D
from keras import optimizers
from keras import applications
from keras.models import Model
from keras.utils.np_utils import to_categorical
img_width, img_height = 160,120
train_data_dir = './data/train'
validation_data_dir = './data/validation'
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 128
train_generator = datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical')
validation_generator = datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical')
model = Sequential()
model.add(Convolution2D(32, (3, 3), input_shape=(img_width, img_height,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model = Sequential()
model.add(Convolution2D(32, (3, 3), input_shape=(img_width, img_height,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model = Sequential()
model.add(Convolution2D(32, (3, 3), input_shape=(img_width, img_height,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
nb_epochs = 100
nb_train_samples = 3000
nb_validation_samples = 600
nb_classes = 3
tb = TensorBoard(log_dir="logs/{}".format(time()))
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=nb_epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size,
callbacks=[tb]
)
model.save('./data/models/beispiel2.1.h5')
Ergebnisse
Das Ergebnis hat uns überrascht: Auch dieses Modell erlangt eine Genauigkeit von ca. 99%! Für die drei Klassen haben wir jeweils 1000 Bilder hinterlegt und jeweils 200 davon für die Validierung benutzt. Die Berechnung dauerte hierbei stolze 27 Minuten. Der Videobeweis ist auf der Startseite zu sehen.
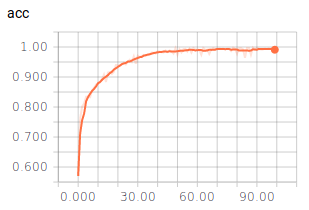
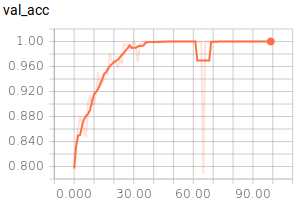
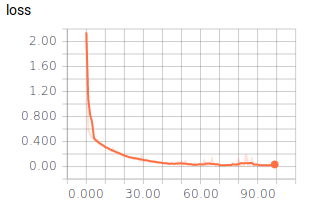
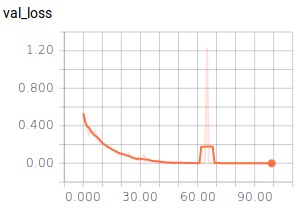
Fazit¶
In dieser Arbeit haben wir gezeigt, dass mit Hilfe von Convolutional Neural Networks die Umsetzung eines autonomen Fahrzeugs möglich ist. Die größte Schwierigkeit war hierbei nicht die Programmierleistung, sondern das Erzeugen von geeigneten Trainingsbildern. Die Bilder müssen markante Unterschiede aufweisen, um erlernbar zu sein. Des Weiteren ist die Wahl der für diesen Fall richtigen Aktivierungsfunktionen und Kostenfunktionen entscheidend. Die Berechnungen für das autonome Fahren werden aufgrund der Rechenzeit nicht auf dem Auto, sondern auf dem Desktop-Rechner ausgeführt. Die Daten werden dazu über WLAN kommuniziert. Dennoch dauert die Berechnung der Vorhersage eine gewisse Zeit, sodass das Auto für die im Video dargestellten drei Runden ca. eine Stunde Fahrtzeit benötigt hat. Es ist erstaunlich, wie gut das Auto die Strecke bewältigt und auch begangene Fehler korrigiert. Dabei können wir jedoch nicht beurteilen, ob dies tatsächlich Fahrfehler sind oder ob wir diese Fehler dem Auto “beigebracht” haben.