Editor-Trick des Tages: Zen Mode¶
Wenn Sie an Ihren Programmen schreiben, brauchen Sie nicht immer alle Funktionalitäten von VSCode. Die Balken an den Seiten und unten können stören, wenn Sie sich nur auf den aktuellen Code konzentrieren wollen.
Dazu können Sie den Zen Mode von VSCode aktivieren. Drücken Sie Ctrl + K und dann Z. Jetzt wird der Editor maximiert und die Teile des Editors, die nicht unmittelbar mit dem Schreiben der aktuellen Datei zu tun haben, werden ausgeblendet.
Um den Zen Mode zu beenden, drücken Sie zweimal Escape.
Einschub: Besprechung von Aufgabe 10-02 (Rekursion)¶
Eingabe: "Beispiel"
Ausgabe: "B(e(i(sp)i)e)l"Vorgegebene Struktur:
def add_brackets(eingabe):
if len(eingabe) <= 2:
pass # "pass" ist in Python ein Befehl, der absolut nichts tut.
# Wir verwenden ihn hier, damit die Funktion ausgeführt
# werden kann, ohne dass wir die Details implementieren
# müssen.
# Ersetzen Sie beide Vorkommen von "pass" durch Ihren
# eigenen Code.
else:
pass
# Erwartete Ausgabe: E(i(n(g(a(b(e( (m(i(t( (u(n(g(e(r)a)d)e)r) )Z)e)i)c)h)e)n)z)a)h)l
print(add_brackets("Eingabe mit ungerader Zeichenzahl"))
# Erwartete Ausgabe: E(i(n(g(a(b(e( (m(i(t( (ge)r)a)d)e)r) )A)n)z)a)h)l
print(add_brackets("Eingabe mit gerader Anzahl"))
Guter Programmierstil in Python¶
Wir haben in den letzten Wochen schon gelegentlich darüber gesprochen, an welche Konventionen Sie sich beim Programmieren halten können, um gut lesbaren (und dadurch gut wartbaren) Code zu produzieren.
Einer der Grundsätze von Python lautet Readability counts. Deshalb gibt es eine formalisierte Sammlung an Empfehlungen für Stilfragen beim Programmieren, die Teil der technischen Spezifikation von Python ist. Diese Sammlung heißt PEP8.
PEP steht für Python Enhancement Proposal. Alle PEPs sind unter https://www.python.org/dev/peps/ abrufbar, sortiert nach allgemeinen Themen. Hier können Sie z.B. nachlesen, warum Python 2 nicht weiterentwickelt wird und die Migration zu Python 3 schon seit 2011 empfohlen wird: PEP 404 -- Python 2.8 Un-release Schedule
In den PEPs können Sie nachlesen, wie die Sprache Python sich über die Jahre hinweg weiterentwickelt, basierend auf Vorschlägen aus der Developer-Mailingliste. Als Hilfe beim Programmieren werden Sie weiterhin die Dokumentation und StackOverflow verwenden, aber wenn Sie sich mal fragen, warum bestimmte Verhaltensweisen von Python so und nicht anders konstruiert wurden, werden Sie in der PEP-Liste vielleicht fündig.
Im Text von PEPs finden Sie oft das Akronym BDFL. BDFL steht für Benevolent Dictator for Life, ein Titel, den Guido van Rossum - der Erfinder von Python - bis Mitte 2018 innehatte. Historisch war ein Statement des BDFL oft der entscheidende Impuls für die Annahme oder Ablehnung einzelner PEP-Vorschläge.
PEP8¶
In PEP8 sind Empfehlungen gelistet, wie wir Pythoncode verfassen. Da diese Empfehlungen exzessiv in der Community diskutiert wurden und inzwischen Standard sind, gibt es Tools zum Prüfen der Einhaltung von PEP8-Richtlinien.
Auch die Python-Extension, die wir in VSCode verwenden, kann das für uns erledigen. Um die Extension dafür einzurichten, tun wir folgendes:
- Mit
Ctrl + Shift + Pdie Command Palette öffnen - Eingeben:
>python select linter - Kommando mit
Enterbestätigen - In der Eingabezeile, die jetzt erscheint,
pep8eingeben und mitEnterbestätigen.
pep8 installieren: Falls VSCode Sie dazu auffordert, pep8 zu installieren, können Sie das tun. Auf den Uni-PCs werden installierte Pakete allerdings nachts wieder gelöscht...
Linter sind Tools, die Ihren Code automatisch auf die Einhaltung vordefinierter Vorgaben prüfen. Dabei kann man die Fehler entweder automatisch beheben lassen oder sich einfach anzeigen lassen, wo Unstimmigkeiten gefunden wurden, um sie per Hand zu beheben.
Je nachdem, wie Ihr Editor eingestellt ist, wird Ihr Code nach der Auswahl des pep8-Linters entweder direkt analysiert, oder Sie müssen den Linter explizit ausführen (Command Palette öffnen und >python run linting ausführen).
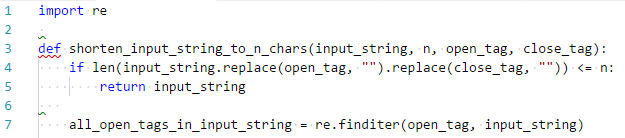
Wie Sie sehen, werden Fehler rot unterstrichen, wie man das z.B. von Word kennt.
Wenn Sie sich alle Fehler in der Datei anzeigen lassen möchten, können Sie die Liste aller Probleme entweder im Menü oben unter View -> Problems anzeigen lassen oder den Befehl in der Command Palette eingeben oder den Shortcut dafür verwenden (bei mir Ctrl + Shift + M). Sie sehen dann in etwa Folgendes:
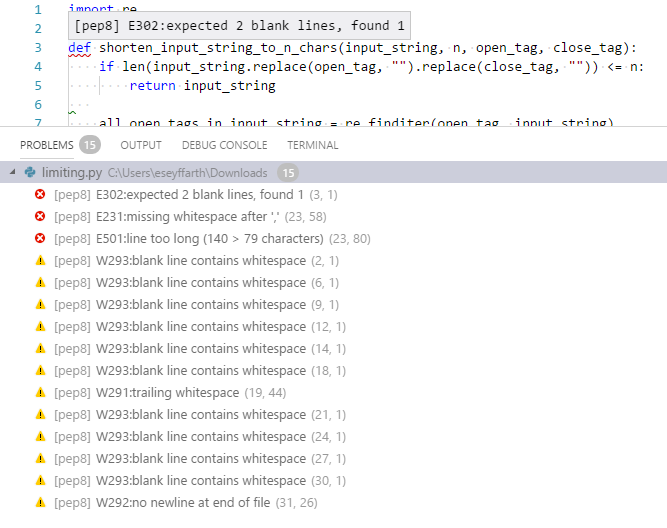
Die Fehlermeldungen sind meist einfach zu lesen.
In meiner Liste oben sind drei Errors - klare Verstöße gegen PEP8 - und einige Warnungen zu sehen. (Die Fehlercodes sind auf der Webseite des pep8-Tools aufgeschlüsselt.)
Jede Zeile in der Liste der "Problems" hat folgendes Format:
[pep8]- Name des Tools, das die Probleme entdeckt hat. (Wenn wir einen anderen Linter wählen, steht hier auch ein anderer Name.)E302:- Fehlercode. Den Code können Sie googeln oder in derpep8-Doku nachlesen.expected 2 blank lines, found 1- sprachliche Beschreibung des Problems. Meistens informativ genug, um das Problem zu beseitigen.(3, 1)- Problem wurde in Zeile3an Position1(Zeilenanfang) lokalisiert. Sie können die Zeilennummer im Editor suchen und das Problem identifizieren. Oder Sie klicken auf einen Eintrag in der Liste der Probleme, dann wird die entsprechende Codezeile markiert, sodass Sie nicht suchen müssen.
Aufgabe¶
- Kopieren Sie den folgenden Code in eine neue Datei in VSCode und speichern Sie das Programm als Pythondatei ab. Lassen Sie sich dann vom Linter alle Probleme des Codes anzeigen. Können Sie anhand der Hinweise das Programm so umschreiben, dass der Linter zufrieden ist?
BNC_PATH = "D:/corpora_and_data/english/annotated/BNC/BNC-parsed/bnc-fi-prsd.txt"
def collect_plural_nouns(bncpath):
plurals = set()
with open( bncpath, "r", encoding="utf8" ) as bncfile :
for line in bncfile:
if line.strip() != False:
if "\tNNS\t" in line:
#print(line)
plurals.add(line.split()[1])
with open("plurals.txt", "w", encoding="utf8") as outfile:
for v in plurals:
print("\"{}\", ".format( v.lower() ), file=outfile, end="")
return plurals
words = collect_plural_nouns(BNC_PATH)
#print(words)
Nicht immer wollen wir PEP8 hundertprozentig befolgen. Die Regel, dass Zeilen nicht länger als 80 Zeichen sein sollen, ist zum Beispiel bei vielen Pythonistas unbeliebt: Wegen der Einrückungen (laut PEP8: 4 Leerzeichen pro Ebene) bleibt einem in komplexen Programmen oft nur wenig Platz für den eigentlichen Code.
Trotzdem ist es empfehlenswert, dass Sie sich mit den Regeln von PEP8 vertraut machen. Gewöhnen Sie sich an, in VSCode vor der Fertigstellung von Programmen immer mindestens einmal die Probleme vom Linter ausgeben zu lassen und pro Eintrag in der Liste bewusst zu entscheiden, ob Sie dagegen etwas unternehmen möchten.
Debugging¶
Die Hinweise, die wir vom Linter bekommen, sind übrigens nur ästhetischer Natur: Normalerweise ändert ein PEP8-Verstoß (oder dessen Behebung) nichts am Verhalten des Programms.
Es gibt zum Glück auch Tools, die uns helfen, andere Formen von Programmierfehlern zu finden und zu lösen: Solche Fehler, bei denen das Programm nicht abstürzt und auch kein Linter anspringt, die aber dazu führen, dass der Output des Programms nicht den Erwartungen entspricht.
Hier ein typisches Beispiel aus meiner Anfangszeit als Programmiererin:
# Aufgabe: Alle Zeichen aus einem vom User eingegebenen String
# in einer Liste sammeln
def collect_chars_from_string(input_string):
output_list = []
for c in input_string:
# Anzeige des aktuellen Zeichens
print("aktuelles Zeichen: {}".format(c))
# Aktuelles Zeichen an die Liste anhängen
output_list = output_list.append(c)
return output_list
full_string = input("Geben Sie irgendetwas ein: ")
characters = collect_chars_from_string(full_string)
print(characters)
Ausgabe des Programms:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-1-1747c8b7971d> in <module>()
14
15 full_string = input("Geben Sie irgendetwas ein: ")
---> 16 characters = collect_chars_from_string(full_string)
17
18 print(characters)
<ipython-input-1-1747c8b7971d> in collect_chars_from_string(input_string)
9
10 # Aktuelles Zeichen an die Liste anhängen
---> 11 output_list = output_list.append(c)
12
13 return output_list
AttributeError: 'NoneType' object has no attribute 'append'
Der Linter hilft uns hier nicht weiter: Es werden höchstens Warnungen angezeigt, aber keine Errors (das Programm ist ja auch ausführbar).
Mit dem Debugger in VSCode können wir das Programm Zeile für Zeile ausführen und prüfen, ob es in jedem Schritt wirklich das tut, was gewünscht ist. Um den Debugger zu starten, können Sie links im Menü auf das Debugger-Symbol klicken oder die Command Palette verwenden (Kommando: >view show debug).
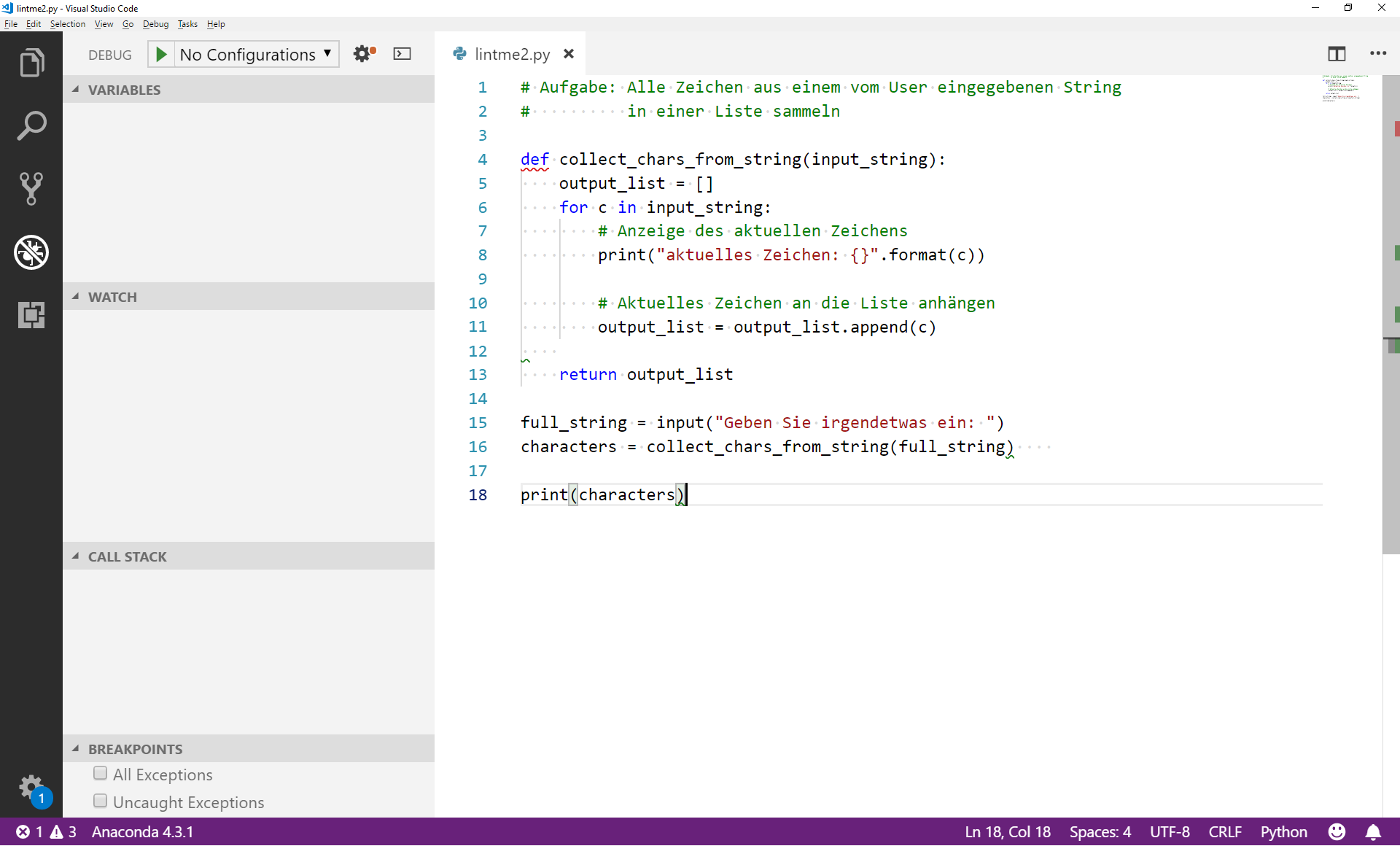
Links sehen wir eine (bisher leere) Übersicht über Variablen, Watches, den Call Stack und die Breakpoints.
Variables wird später beim Starten des Debuggers alle Namen und ihre jeweiligen Werte auflisten.
Watches können wir selbst anlegen: So können wir den Wert bestimmter Variablen bzw. komplexer Ausdrücke zu jedem Zeitpunkt auf den ersten Blick erkennen.
Der Call Stack ist verwandt mit dem Traceback, den wir schon aus unseren Fehlermeldungen kennen: Hier sehen wir, ob wir uns gerade in einem Funktionsaufruf befinden bzw. wie verschachtelt die aktuellen Funktionsaufrufe sind.
Breakpoints sind für den Start besonders wichtig: Damit legen wir fest, wann der Debugger die Ausführung des Programms pausiert, damit wir uns den Zustand des Programms näher anschauen können. Der Interpreter wird das Programm zunächst normal ausführen; beim ersten Breakpoint hält er an und wir können prüfen, wie das Programm sich verhält.
Für die aktuelle Übung setzen wir den Breakpoint einfach in die erste Zeile, die vom Interpreter ausgeführt wird. Das ist Zeile 15 im Code oben. Um den Breakpoint zu setzen, klicken wir mit der Maus links neben die Zeilennummer, sodass ein roter Punkt erscheint. Wir können beliebig viele Breakpoints setzen, z.B. in Zeile 15 und zusätzlich in Zeile 13 (mit der Vermutung, dass die Rückgabe der Liste ein Problem ist).
Wie Sie sehen, erscheinen unsere beiden Breakpoints sofort unten links in der Übersicht.
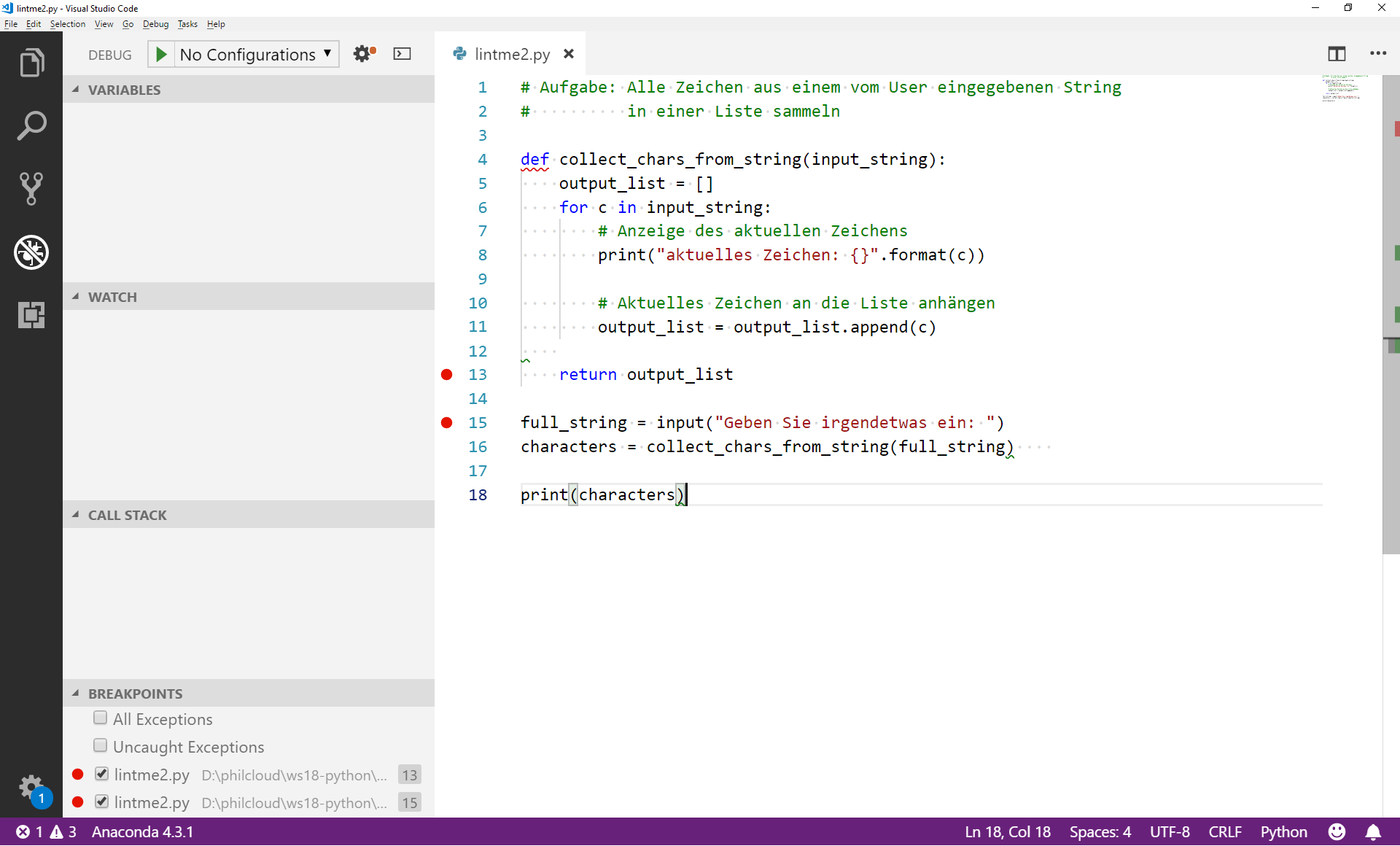
Es kann losgehen! Starten Sie den Debugger mit dem "Play"-Symbol oben links oder durch Auswahl von Debug -> Start Debugging oder durch Verwendung des Keyboard Shortcuts (bei mir: F5) oder mit der Command Palette. Wir müssen dem Debugger zusätzlich noch sagen, dass der Python-Interpreter verwendet werden soll (Python).
Da wir einen Breakpoint in Zeile 15 gesetzt haben, pausiert der Interpreter an diesem Punkt. Sie sehen jetzt, dass die Boxen links sich gefüllt haben: Unter Variables sind jetzt einige Werte verfügbar. Wie in der Sitzung vom 30.10.2018 sehen wir, dass die __builtins__ Teil des lokalen Namespace sind. Außerdem ist die von uns definierte Funktion, collect_chars_from_input_string(), bekannt, weil der Interpreter sie in den Speicher gelesen hat, bevor er in Zeile 15 angekommen ist.
Im Call Stack sehen wir, dass wir uns momentan im <module> befinden - also auf der obersten Hierarchieebene des Programms. Wir erfahren hier auch, dass der Debugger in Zeile 15, Position 1 angehalten hat, und zwar in der Datei lintme2.py.
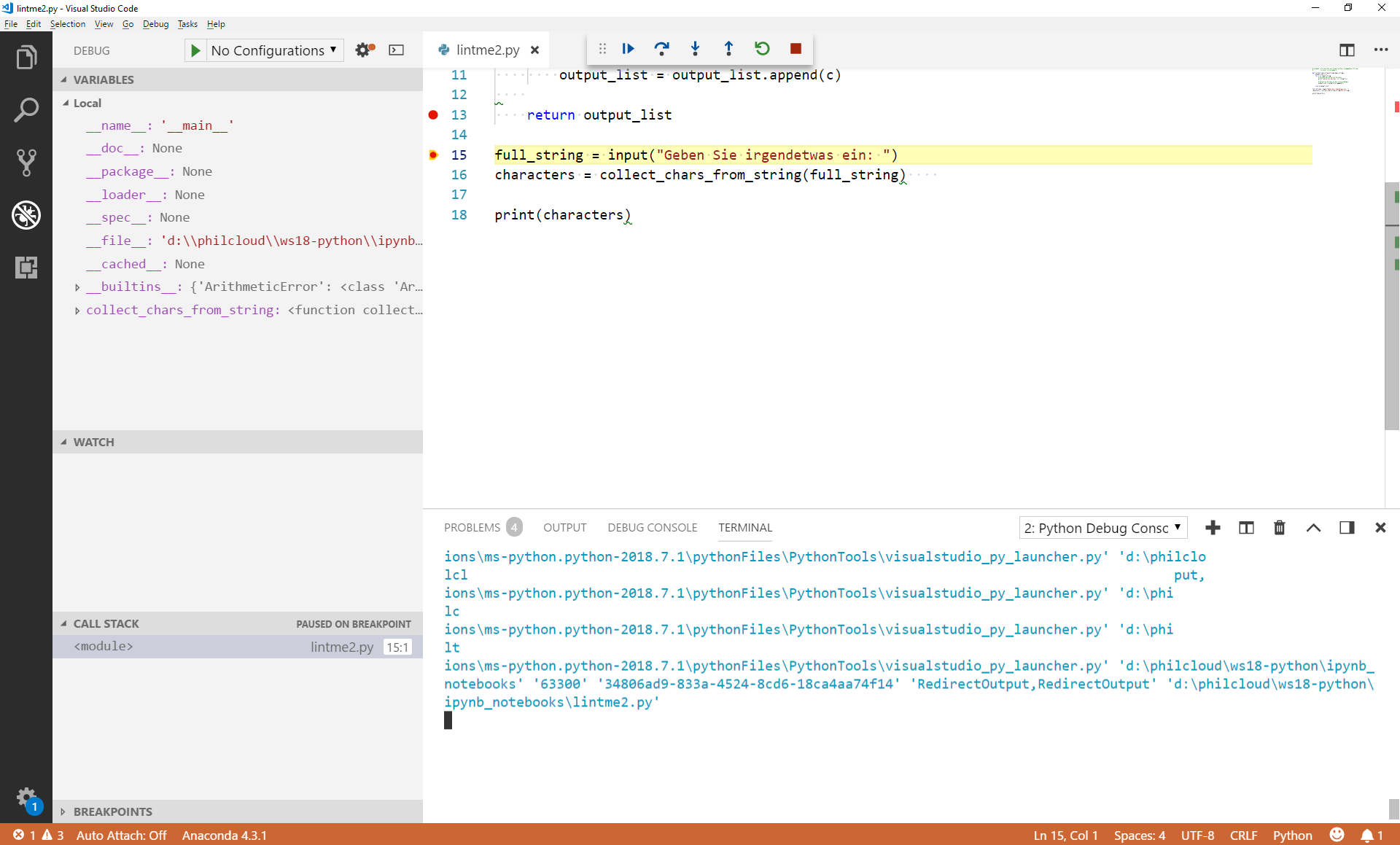
Da dieser Teil des Programms noch nicht so interessant ist, wollen wir einen Schritt weitergehen. Dazu haben wir mehrere Möglichkeiten: Wir können in der Steuerleiste des Debuggers (oben Mitte) entweder bis zum nächsten Breakpoint "vorspulen" (erster Knopf); oder wir springen in die nächste ausführbare Zeile des Programms (zweiter Knopf); oder wir springen in die Methode, die als nächstes ausgeführt werden soll, hinein (dritter Knopf).
Der Interpreter hält in Zeile 15 an, bevor die Zeile tatsächlich ausgeführt wird. Da wir uns nicht dafür interessieren, was bei input() passiert (die Methode ist Teil der Sprache Python und mit hoher Wahrscheinlichkeit korrekt implementiert...), wählen wir Option 2 und springen in die nächste Zeile, also in Zeile 16. Zwischendurch geben wir den String unten im Terminal ein, nach dem wir gefragt werden, und bestätigen die Eingabe mit Enter.
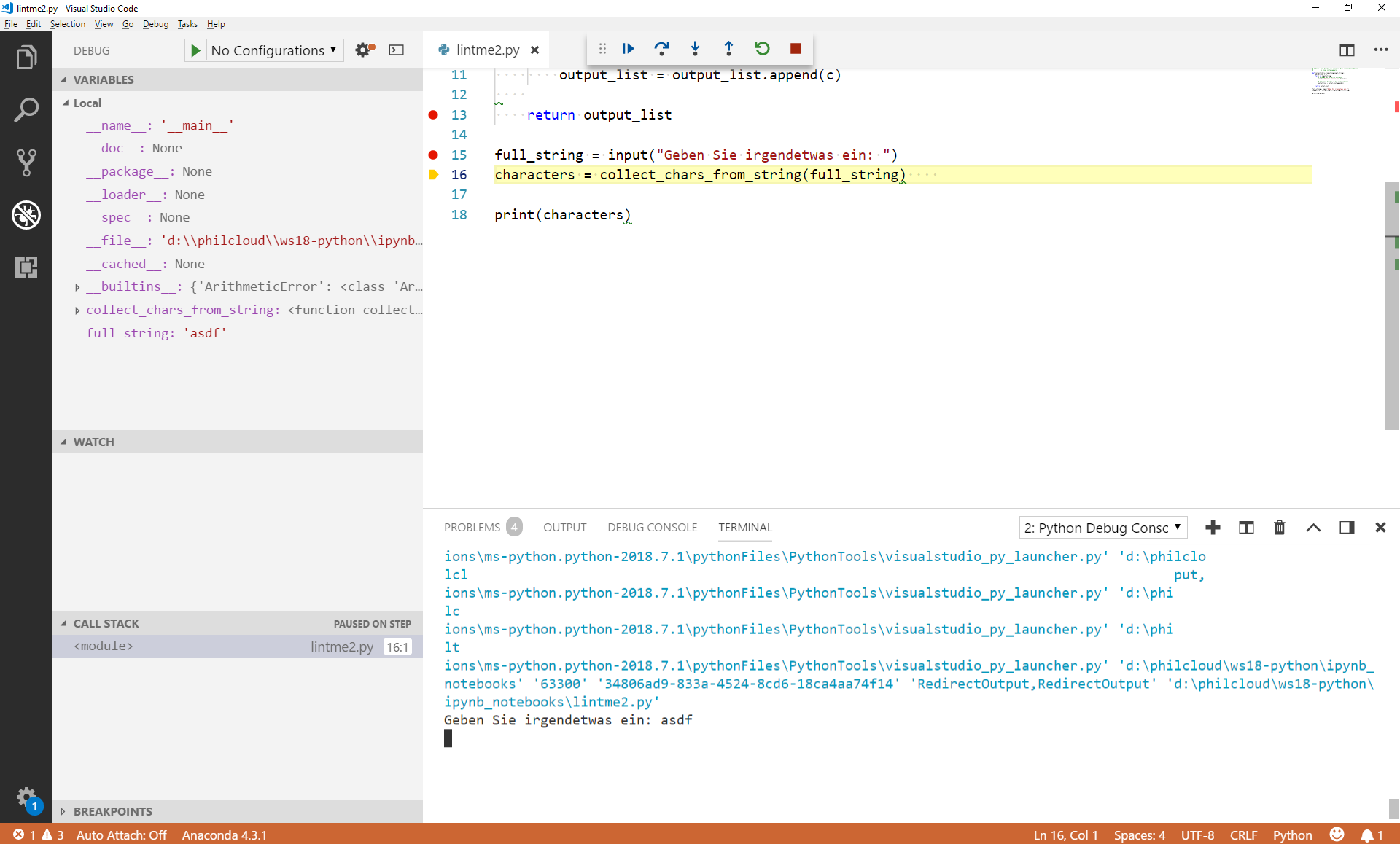
Wir sehen jetzt, dass links unter Variables ein neuer Eintrag erschienen ist: Der Interpreter hat nach dem Ausführen von Zeile 15 einen neuen Namen dem Namespace hinzugefügt, und zwar die Variable full_string, in der der Wert asdf gespeichert ist.
Als nächstes können wir in die Funktion collect_chars_from_string() springen, indem wir den dritten Knopf in der Steuerleiste wählen. In der Variables-Box ändert sich jetzt so einiges: Es wird jetzt der Namespace der Funktion angezeigt. Er enthält lokale Variablen, nämlich output_list und c, die aber in Zeile 5 noch nicht belegt sind; und außerdem Argumente, also die Werte, die beim Aufruf der Funktion übergeben wurden.
Im Call Stack sehen wir, dass der Stack gewachsen ist: Wir sind in die Funktion collect_chars_from_string() gesprungen, also wird diese Funktion oberhalb des vorher vorhandenen Eintrags angezeigt.
Call stack bedeutet wörtlich "Aufrufstapel" und bezeichnet ein Konstrukt, das einem Stapel tatsächlich ähnelt. Der Stapel wird leer angelegt (vgl. erstes Bild vor dem Starten des Debuggers). Dann wird ein Element auf den Stapel gelegt (vgl. <module> im Bild zum ersten Breakpoint). Alle weiteren Elemente werden oberhalb der bestehenden Einträge gestapelt. Der Stack kann dann nur in der gleichen Reihenfolge wieder abgebaut werden, in der er aufgebaut wurde: Erst muss das oberste Element ordnungsgemäß beendet werden, dann das nächstobere usw.
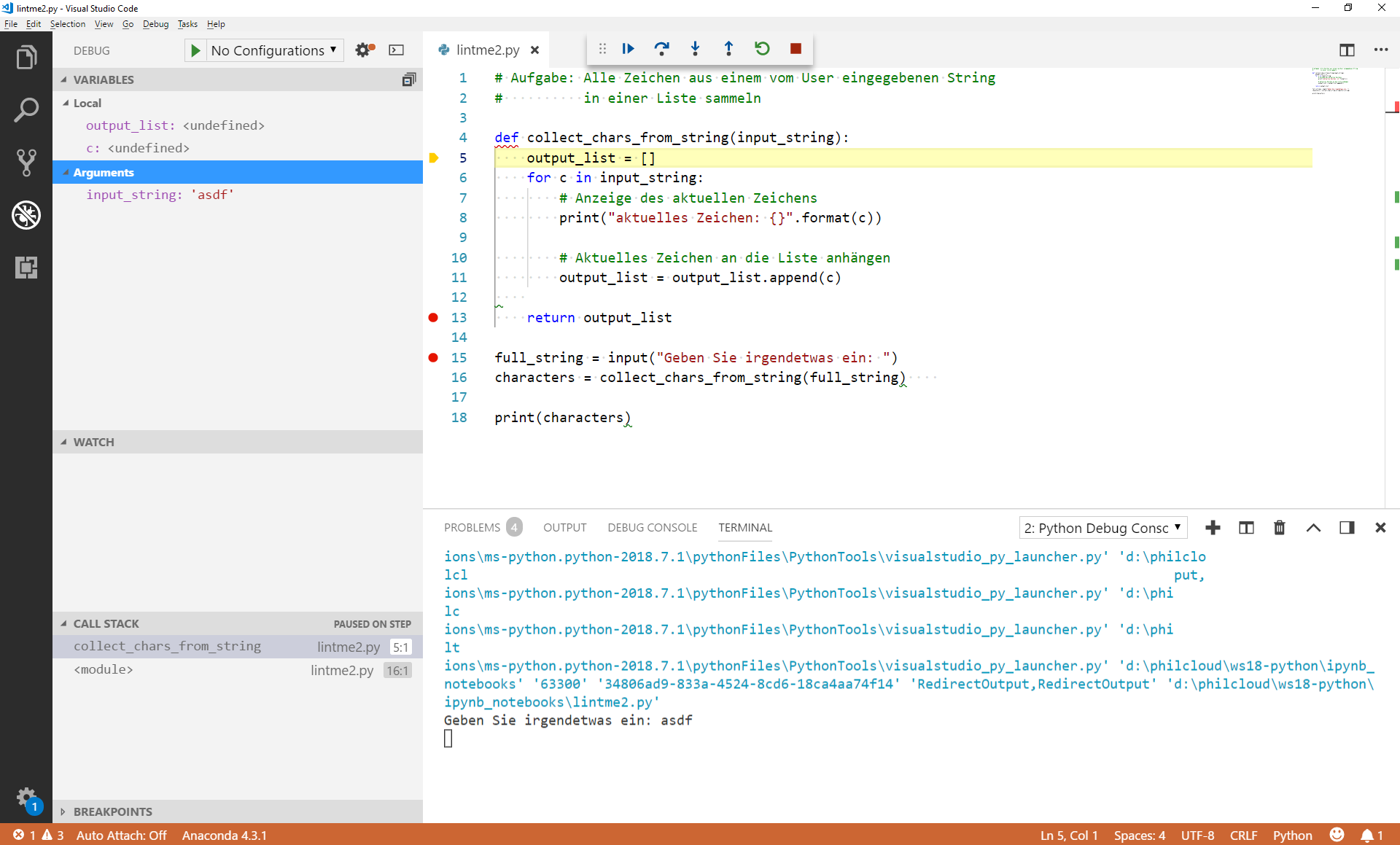
Da wir am Schluss der Funktion einen Breakpoint gesetzt haben, können wir als nächstes mal den ersten Knopf in der Steuerleiste testen. Oder?
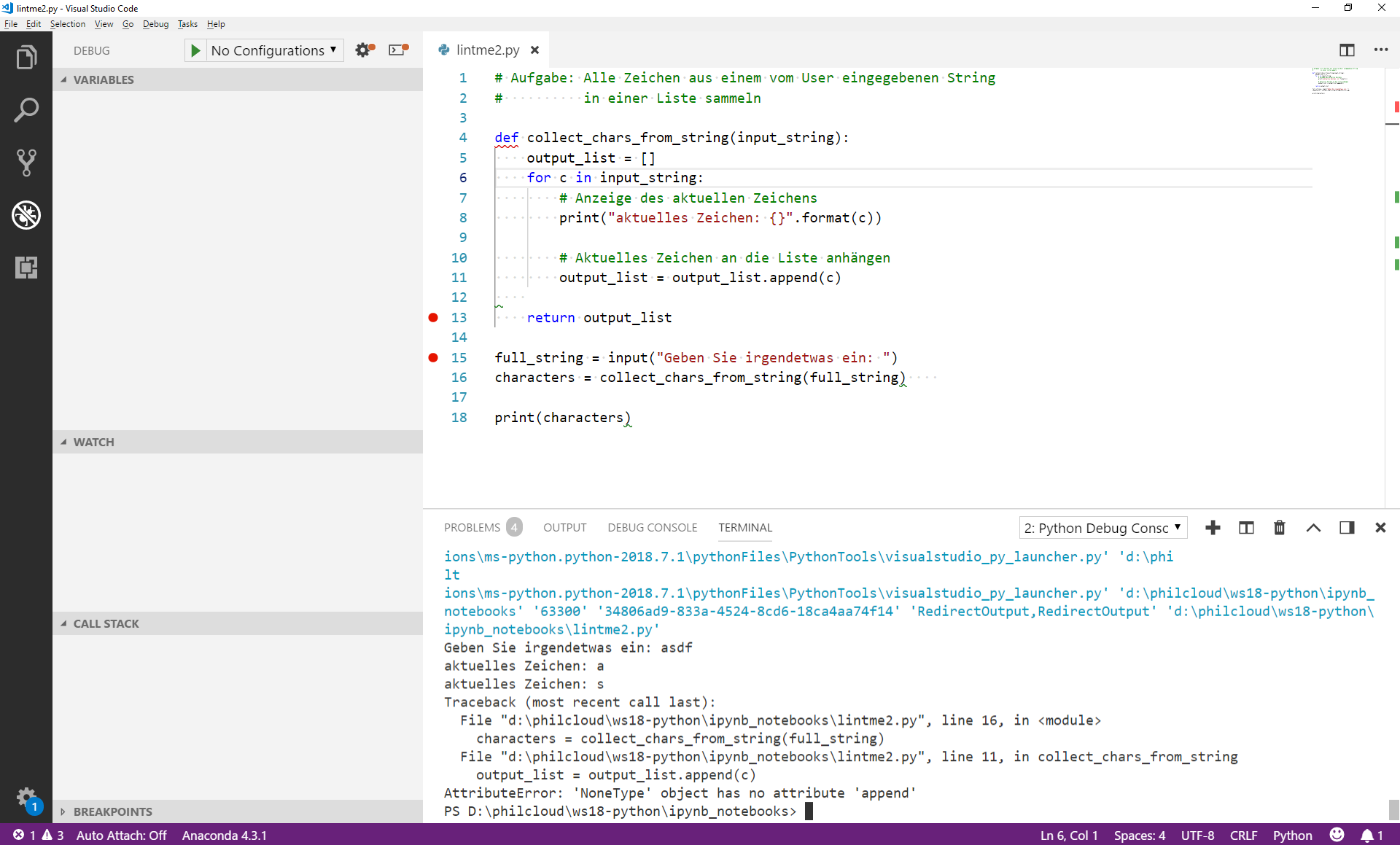
Schade. Der Fehler tritt also irgendwo zwischen Zeile 5 und Zeile 13 auf. (Natürlich konnten wir das eigentlich auch schon an der ursprünglichen Ausgabe sehen.)
Starten wir den Debugger neu. Diesmal wollen wir genau wissen, welchen Wert die Variablen output_list und c zu jedem Zeitpunkt haben. Und wir klicken uns per Hand Schritt für Schritt durch die Funktion und durch die Schleife, um zu sehen, wo das Problem ist.
Um die Variablen im Auge zu behalten, die uns interessieren, richten wir eine Watch ein. Neben dem Wort "Watch" klicken wir auf das +, um einen Ausdruck einzugeben, dessen Wert immer angezeigt werden soll. Mit Enter bestätigen wir die Eingabe.
Richten Sie zwei Watches ein: Eine für output_list und eine für c.
Wenn wir den Debugger neu starten, sieht die Box für die Watches fehlerhaft aus: Es wird bei beiden Variablen ein NameError angezeigt. Das liegt daran, dass wir beim ersten Breakpoint - in Zeile 15 - noch nicht den Namespace betreten haben, in dem diese Variablen bekannt sind. Das ist nicht weiter schlimm. Klicken Sie sich weiter durch das Programm (Eingabe eines Strings zwischendurch nicht vergessen). Denken Sie bei Zeile 16 daran, "Step Into" zu wählen statt "Step Over".
Sobald die Variablen, die uns interessieren, angelegt werden - in Zeile 5 bzw. 6 -, verschwinden die NameErrors.
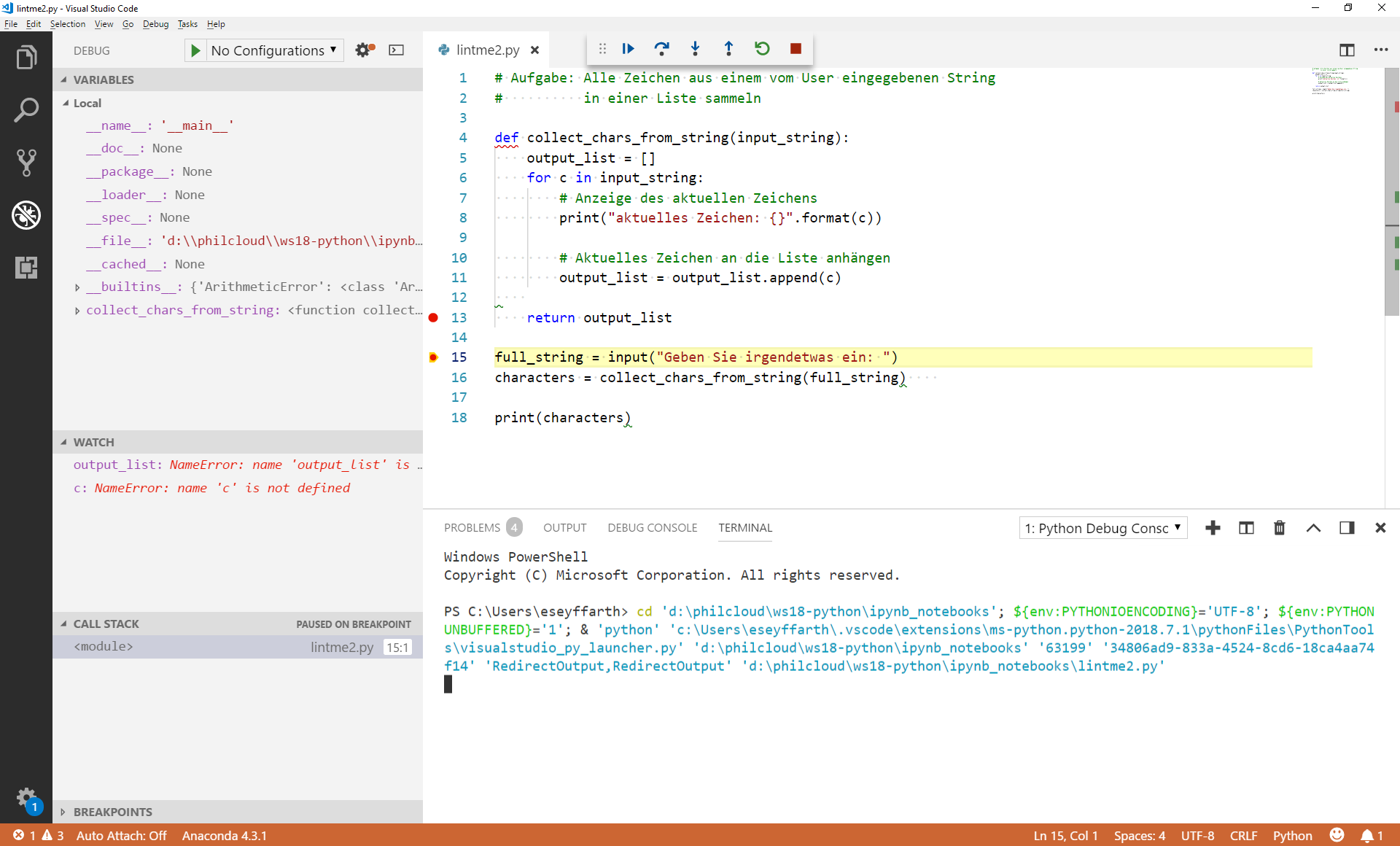
Sobald Sie z.B. Zeile 8 erreichen, sind beide NameErrors weg. Stattdessen werden die aktuellen Werte der Variablen angezeigt. Bisher sieht alles noch so aus wie erwartet: Die Liste ist leer (weil noch kein Element eingefügt wurde), das c ist das erste Zeichen des Eingabe-Strings.

In der Watch-Box werden Werte, die sich vor kurzem geändert haben, gesondert hervorgehoben (vgl. den Wert von c im letzten Screenshot, bei dem der Debugger als letztes Zeile 6 ausgeführt hat, die den Wert von c festlegt).
Klicken Sie "Step Over", bis Sie im nächsten Schleifendurchlauf ankommen. Sie sehen folgendes:
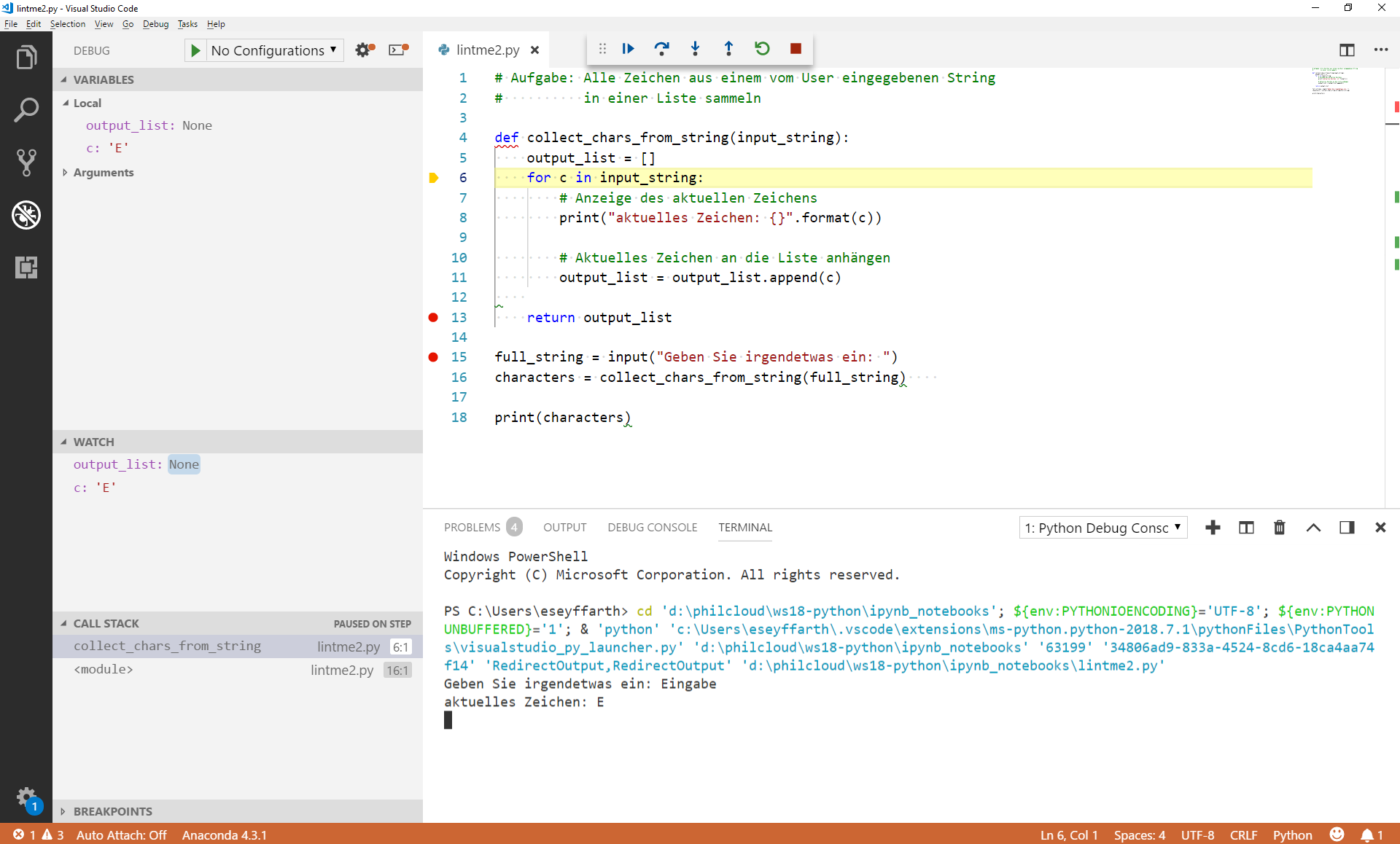

Der Typ der output_list hat sich geändert. Wir wollten alle Zeichen nacheinander in einer Liste sammeln, aber jetzt hat die Variable den Typ und den Wert None. Damit können wir nicht operieren.
Deshalb wird der nächste Versuch, Zeile 11 auszuführen, fehlschlagen. (Überzeugen Sie sich davon selbst, indem Sie noch einige Male "Step Over" klicken, bis das Programm abstürzt.)
Der Debugger zeigt uns genau, dass zwischen Zeile 11 (im ersten Schleifendurchlauf) und Zeile 6 (wenn sie den zweiten Schleifendurchlauf einleitet) ein Problem auftritt. Wir wissen jetzt also, dass wir in Zeile 11 ansetzen müssen, um das Problem zu beseitigen.
Möglicherweise haben einige von Ihnen bisher in den Übungen viele Aufrufe von print() in den Code eingebaut, um zwischendurch zu sehen, welchen Wert einzelne Variablen haben. Dagegen ist im Übungskontext auch nichts einzuwenden. In produktiven Systemen soll print() typischerweise nur dann verwendet werden, wenn es ein integraler Bestandteil der Funktionalität des jeweiligen Programms ist.
Eine weitere Funktion des Debuggers, die wir eben noch gar nicht genutzt haben, ist die Debug Console. Unten beim Terminal sehen Sie eine Schaltfläche zum Anzeigen dieser Konsole. Sie ermöglicht es Ihnen, während des Debuggens beliebigen Code wie in einer REPL auszuführen, und zwar unter Verwendung aktueller Variablenwerte. Probieren Sie die Konsole demnächst aus, wenn Sie debuggen und sich für aktuelle Werte nur einmal interessieren (Watches sind eher geeignet für Variablen, die sich oft verändern, z.B. im Verlauf von Schleifen).
Effiziente Programmierung¶
Inzwischen haben wir gesehen, wie wir Fehler während der Laufzeit mit try und except behandeln können und wie wir mit dem Debugger herausfinden können, an welcher Stelle unser Pythoncode fehlerhaft ist.
Um noch besser und effizienter zu programmieren, hilft es, wenn wir eine Vorstellung von der Komplexität einzelner Teile unseres Programms haben.
Oft gibt es mehrere Möglichkeiten, bestimmte Dinge mit Pythonbefehlen zu erreichen. Erinnern Sie sich beispielsweise an die Aufgabe, einen String umzudrehen. Wir hatten auf StackOverflow folgende Lösung dafür gefunden:
def reverse_string_with_slicing(input_string):
output_string = input_string[::-1]
return output_string
print(reverse_string_with_slicing("Hallo Welt"))
Wenn wir diese Lösung nicht kennen würden, könnten wir einen kleinen Umweg machen: Wir wandeln den String zuerst in eine Liste um und fügen die Elemente dieser Liste dann nach und nach einem neuen String hinzu.
def reverse_string_with_pop(input_string):
output_string = ""
input_string_as_list = list(input_string)
while len(input_string_as_list) > 0:
output_string += input_string_as_list.pop()
return output_string
print(reverse_string_with_pop("Hallo Welt"))
Wie Sie sehen, verhalten beide Funktionen sich gleich. Welche Lösung leichter zu lesen ist, ist nicht ganz klar - die Anweisung input_string[::-1] ist nicht so einfach zu verstehen, aber die Lösung mit der Liste hat mehr Codezeilen und sieht damit komplizierter aus.
Was uns darüber hinaus interessiert, ist die Dauer jeder Lösung. Daran, wie lange die Funktion braucht, können wir in etwa ablesen, wie effizient sie programmiert ist.
Um die Dauer zu messen, die ein Codebeispiel benötigt, können wir timeit verwenden. So setzen wir timeit ein:
import timeit # Modul timeit importieren
# erste Funktion definieren
def reverse_string_with_slicing(input_string):
output_string = input_string[::-1]
return output_string
# zweite Funktion definieren
def reverse_string_with_pop(input_string):
output_string = ""
input_string_as_list = list(input_string)
while len(input_string_as_list) > 0:
output_string += input_string_as_list.pop()
return output_string
# Befehl, um die Laufzeit der ersten Funktion zu messen
t1 = timeit.timeit('reverse_string_with_slicing("Hallo Welt")', setup="from __main__ import reverse_string_with_slicing", number=1000000)
print("Dauer für 1000000 Aufrufe von reverse_string_with_slicing(): {}".format(t1))
# Befehl, um die Laufzeit der zweiten Funktion zu messen
t2 = timeit.timeit('reverse_string_with_pop("Hallo Welt")', setup="from __main__ import reverse_string_with_pop", number=1000000)
print("Dauer für 1000000 Aufrufe von reverse_string_with_pop(): {}".format(t2))
Die einzelnen Bestandteile des timeit-Aufrufs:
- Der Befehl, der gemessen werden soll; idealerweise genau ein Funktionsaufruf. So können wir die Dauer der einen gesamten Funktion mit der Dauer der anderen gesamten Funktion vergleichen.
setup: Ein Import-Befehl der Formfrom __main__ import <unsere Funktion>.number: Anzahl der Ausführungen, die getestet werden sollen. Das ist notwendig, weil die Ausführungsdauer auch von anderen Faktoren abhängt als der Effizienz des Codes, sodass nicht immer das exakt gleiche Ergebnis zurückgegeben wird; wenn wir aber, wie im Beispiel oben, jede Funktion 1000000 mal ausführen, kann die Dauer dieser 1000000 Aufrufe aufschlussreich sein (vor allem, um zwei Funktionen zu vergleichen).
In meinem Test hat das Jupyter Notebook folgende Ausgabe erzeugt:
Dauer für 1000000 Aufrufe von reverse_string_with_slicing(): 0.19854170812186567
Dauer für 1000000 Aufrufe von reverse_string_with_pop(): 2.7951870553280287Wir sehen also, dass die Funktion mit Slicing deutlich schneller ist als die Funktion mit pop().
Im Einführungskurs ist es oft schwer, die Effizienz von Programmen einzuschätzen, weil wir uns mit vergleichsweise kleinen Aufgaben beschäftigen. Trotzdem ist es gut, wenn Sie ein Gefühl dafür entwickeln, welche von zwei Lösungen effizienter ist. Vor allem, wenn wir mit großen Datenmengen hantieren, ist Effizienz wünschenswert.
Warum ist jetzt die eine Lösung so viel langsamer als die andere? Überlegen wir mal, welche Operationen für Python aufwendig sind...
- Umwandlungen von einem Datentyp in einen anderen, allgemein: Erzeugen neuer Variablen
- Bedingungen prüfen (z.B.
len(input_string_as_list) > 0) - Operationen auf nicht-veränderlichen Datentypen (wie Strings)
Operationen auf nicht-veränderlichen Datentypen sind deshalb aufwendig, weil faktisch jedesmal ein neues Objekt erzeugt wird. Wenn wir also mit output_string += input_string_as_list.pop() nach und nach den String für die Rückgabe zusammenfügen, erzeugen wir in Wahrheit jedesmal einen neuen String, weil Stringoperationen den ursprünglichen String nicht verändern können.
Um nicht-veränderliche Datentypen zu verändern, müssen wir also notwendigerweise immer ein neues Objekt erzeugen.
Bei veränderlichen Datentypen gibt es meist mehrere Möglichkeiten zum Verändern des Wertes: Die, die das Objekt direkt in place verändern, und die, die sich so verhalten wie das += eben beim String.
Aufgabe¶
- Führen Sie
timeitauf die folgenden Funktionen aus, die beide die Aufgabe haben, einer Liste alle Zahlen zwischen 0 und 1000 hinzuzufügen. Passen Ihre Beobachtungen zu dem, was Sie über veränderliche Datentypen wissen? Tipp: Wählen Sie zunächst nur 1000 Wiederholungen aus, dann ggf. 10000. Sie sollten bereits bei diesen Zahlen einen Unterschied bemerken.
import timeit
# erste Funktion definieren
def add_to_list_with_plus():
my_list = []
for i in range(1000):
my_list = my_list + [i]
return my_list
# zweite Funktion definieren
def add_to_list_with_append():
my_list = []
for i in range(1000):
my_list.append(i)
return my_list
# Ihre Befehle zum timen der Funktionen
Ein weiterer guter Grundsatz für effiziente Programmierung ist: Vermeiden Sie Schleifen, wann immer es möglich ist. Einige Möglichkeiten, wie Sie das erreichen können:
- Comprehensions verwenden, statt mit
for-Schleifen eine Liste/Menge/ein Dictionary nach und nach mit Werten zu füllen. join()verwenden, statt einen String mit einerfor-Schleife nach und nach zu füllen.- Bevor Sie mehrere
for-Schleifen ineinander verschachteln: Überlegen Sie, ob es eine andere Möglichkeit gibt, z.B. zwei aufeinanderfolgendefor-Schleifen (nicht verschachtelt). - In Ihren Schleifen sollten nur diejenigen Befehle stehen, die absolut notwendig Teil der Schleife sein müssen. Definitionen von z.B. regulären Ausdrücken sind fast immer außerhalb der Schleife besser aufgehoben.
importsoll niemals in Code-Abschnitten stehen, die wiederholt ausgeführt werden!Die Funktion
map()lässt Sie eine beliebige Funktion auf alle Elemente einer Liste anwenden:Ohne
map:oldlist = ["My", "Hovercraft", "is", "full", "of", "eels"] newlist = [] for word in oldlist: newlist.append(word.upper())
Mit
map:oldlist = ["My", "Hovercraft", "is", "full", "of", "eels"] newlist = map(str.upper, oldlist)
Um einen String aus mehreren Teilstrings zusammenzusetzen, sollten Sie immer format() verwenden. Statt
output = "Das Wort " + "'und'" + " kam im Text " + str(5) + " mal vor"
schreiben Sie lieber:
output = "Das Wort {} kam im Text {} mal vor".format("und", 5)
Insgesamt lohnt es sich meistens, eingebaute Methoden zu verwenden, statt eigene Funktionen zu definieren.
Einen ausführlichen Vergleich verschiedener Lösungen für eine einzige Aufgabe finden Sie hier.
Zusammenfassung¶
Sie haben heute gelernt,
- in VSCode zu prüfen, ob Ihr Code den Vorgaben von PEP8 entspricht
- mit dem Debugger von VSCode ein Programm Schritt für Schritt auszuführen, um fehlerhafte Codezeilen zu identifizieren
- zu messen, wie lange eine vorgegebene Anzahl Ausführungen einer Funktion brauchen, um zu vergleichen, welche Lösung effizienter ist
- Schleifen möglichst selten und möglichst kurz zu schreiben, um effizienten Code zu erzeugen
map()zu verwenden, um eine Funktion auf alle Elemente einer Liste anzuwenden
Projekt: Mastodon-Bot¶
In der Übung morgen werden wir einen Mastodon-Bot zusammen entwickeln, der Sprichwörter verfremdet. Dazu werden drei Gruppen gebildet:
- Die erste Gruppe hat die Aufgabe, einen Account auf Mastodon zu erzeugen und den Code bereitzustellen, mit dem beliebige Texte online auf diesem Account veröffentlicht werden. Benötigte Konzepte: Funktionen, Dokumentation lesen und verstehen.
- Die zweite Gruppe hat die Aufgabe, die Daten vorzubereiten, die zum Verfremden von Sprichwörtern benötigt werden. Dazu bekommt die Gruppe eine Datei, die deutsche Substantive mit Flektionsangaben enthält. Als Ergebnis liefert die Gruppe ein Dictionary bzw. eine Datei, in der die Substantive nach bestimmten Kriterien gruppiert werden. Benötigte Konzepte: Dateien lesen, Dictionarys erzeugen, grundlegende Stringmethoden, Mengen, Funktionen. Optional: Dateien schreiben.
- Die dritte Gruppe bekommt die sortierten Daten von der zweiten Gruppe und verwendet diese, um je ein zufällig ausgewähltes Sprichwort zu verfremden. Benötigte Konzepte: reguläre Ausdrücke, Dictionarys, random, grundlegende Stringmethoden, Funktionen.
Die Daten sehen so aus:
nouns.txt (wird von Gruppe 2 gelesen)
-------------------------------------
...
Laboralltag Masc_Nom_Sg Masc_Dat_Sg Masc_Acc_Sg
Laboranalyse Fem_Nom_Sg Fem_Gen_Sg Fem_Dat_Sg Fem_Acc_Sg
Laboranalytik Fem_Nom_Sg Fem_Gen_Sg Fem_Dat_Sg Fem_Acc_Sg
Laboranforderungsbogen Masc_Nom_Sg Masc_Dat_Sg Masc_Acc_Sg
Laborangestellte Masc_Nom_Sg_Wk Masc_Nom_Pl_St Masc_Acc_Pl_St
Laboranlage Fem_Nom_Sg Fem_Gen_Sg Fem_Dat_Sg Fem_Acc_Sg
Laboranordnung Fem_Nom_Sg Fem_Gen_Sg Fem_Dat_Sg Fem_Acc_Sg
...noun_classes.txt (wird von Gruppe 2 geschrieben)
------------------------------------------------
...
Masc_Acc_Pl+Masc_Acc_Pl+Masc_Dat_Pl+Masc_Dat_Pl+Masc_Gen_Pl+Masc_Gen_Pl+Masc_Nom_Pl+Masc_Nom_Pl Wohnneubauten Quantenalgorithmen Gewerbebauten Rechtskodizes Marktplatzbauten Aluminiumbauten Fahrzeugneubauten Ruderseen Schiffsneubauten Umschaltmechanismen Putzbauten
Neut_Acc_Pl+Neut_Dat_Pl+Neut_Dat_Sg+Neut_Gen_Pl+Neut_Nom_Pl Palmenherzen Papierherzen Eisherzen Palmherzen Herzen Froschherzen Salatherzen
...sprichwoerter.txt (wird von Gruppe 3 gelesen)
---------------------------------------------
...
Gut Ding braucht Weile
Guter Rat ist teuer
Handwerk hat goldenen Boden
Harte Schale, weicher Kern
...Nutzen Sie die Zeit bis morgen, um sich zu überlegen, welche der drei Aufgaben Sie besonders interessiert bzw. mit wem Sie gerne zusammenarbeiten möchten. Wenn Sie keine Wünsche haben, können wir Sie zufällig einteilen.
Jede Gruppe wird von einer der drei Lehrpersonen betreut. Sie müssen also keine Angst haben, dass Sie steckenbleiben oder nicht rechtzeitig fertig werden.